
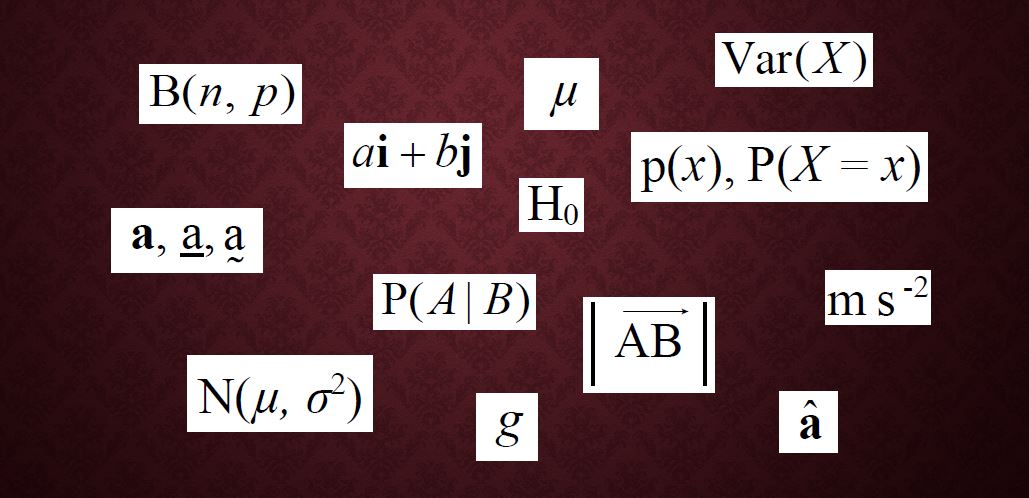
Mathematical notation you need for A-level – part 3
This is part 3 of a series covering the mathematical notation you need for A-level Maths. Click the links below for the previous parts:
Part 1: set notation and miscellaneous symbols
Part 2: other Pure Maths notation
This final instalment covers vectors and the mathematical notation used for Statistics and Mechanics.
You can find an exhaustive list in the appendices to the specification published by your exam board – Edexcel (9MA0), AQA (7357), OCR (H240) and OCR/MEI (H640) – but here you’ll find a little more explanation for the ones that you’re most likely to come across.
The images used here are taken from the Edexcel spec, but the list is the same for all.
Vectors
You’re probably already familiar with the majority of the mathematical notation here from GCSE, but there will be a few items you’re unlikely to have encountered before.
Note: in 7.2 and 7.6, the line above the AB is actually an arrow pointing to the right; it just hasn’t reproduced well here.
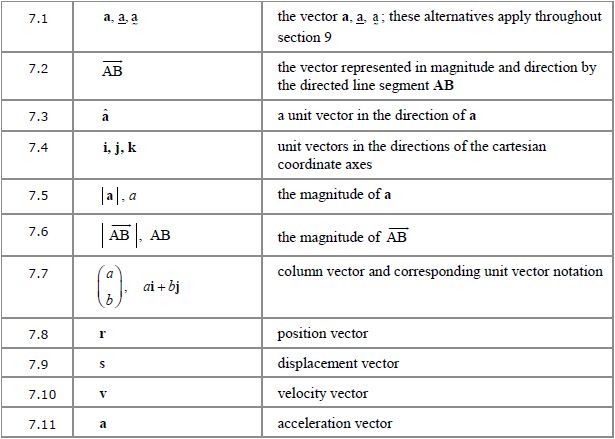
7.1 to 7.2 Describing vectors
Remember, when a lowercase letter is used to represent a vector, it should be in bold text if typed, or underlined (with either a squiggly or a straight line) if handwritten.
 represents the vector from point A to point B. If the arrow is reversed then you have the vector from B to A:
represents the vector from point A to point B. If the arrow is reversed then you have the vector from B to A:  or
or  .
.
7.3 Unit vector
The circumflex (^) above the vector indicates a unit vector:  represents a vector in the same direction as vector
represents a vector in the same direction as vector  , but with a length of exactly one unit, so it’s vector divided by its length (see magnitude, below).
, but with a length of exactly one unit, so it’s vector divided by its length (see magnitude, below).
7.4 and 7.7 i, j, k format
From GCSE you’ll be familiar with column vectors:  means 2 units in the x-direction (normally to the right) and -3 in the y-direction, i.e. 3 down. Similarly, you can have a 3-dimensional vector which also includes a movement in the z-direction – just add the z-component to the bottom of the column vector:
means 2 units in the x-direction (normally to the right) and -3 in the y-direction, i.e. 3 down. Similarly, you can have a 3-dimensional vector which also includes a movement in the z-direction – just add the z-component to the bottom of the column vector: 
 ,
,  and
and  are the unit vectors in the x-, y- and z- directions respectively; in other words, represents a movement of 1 unit in the x-direction.
are the unit vectors in the x-, y- and z- directions respectively; in other words, represents a movement of 1 unit in the x-direction.
So the column vector can alternatively be written as  .
.
Similarly, can be written as  .
.
You’ll often find that vectors are given in , format in questions, but if you find it easier to work with column vectors – I do; it involves less writing, for a start! – then it’s fine to convert them into column vector form… and there’s no need to convert them back again at the end, either.
7.5, 7.6 Magnitude of a vector
As you know from earlier, enclosing something in vertical lines denotes the modulus, or magnitude, of whatever it encloses; in this case it’s the size (length) of a vector, regardless of its direction. Essentially the modulus signs cancel out the arrow, bold text or underlining, so you also have the alternative of simply omitting both, so  and
and  .
.
For a 2-dimensional vector, the two components form the two shorter sides of a right-angled triangle, with the resultant vector being the hypotenuse, so you can find its magnitude using Pythagoras.
For example, if 
then 
This can also be extended to a 3-dimensional vector; it’s equivalent to finding the length of the diagonal of a cuboid.
7.8 to 7.11 Vectors in kinematics
These letters are used for vectors representing position, displacement, velocity and acceleration vectors. The position vector is the one that gives a location relative to the origin, and a displacement vector tells you where the body is in reference to some other point of reference, generally its starting position.
Statistics
You’ll already be familiar with some of the mathematical notation at the beginning of this table, but a lot of the later content will be (quite literally) Greek to you! My explanations may not make much sense to you until you study the relevant topics in more depth, but I’ll do what I can to keep them as simple as possible!
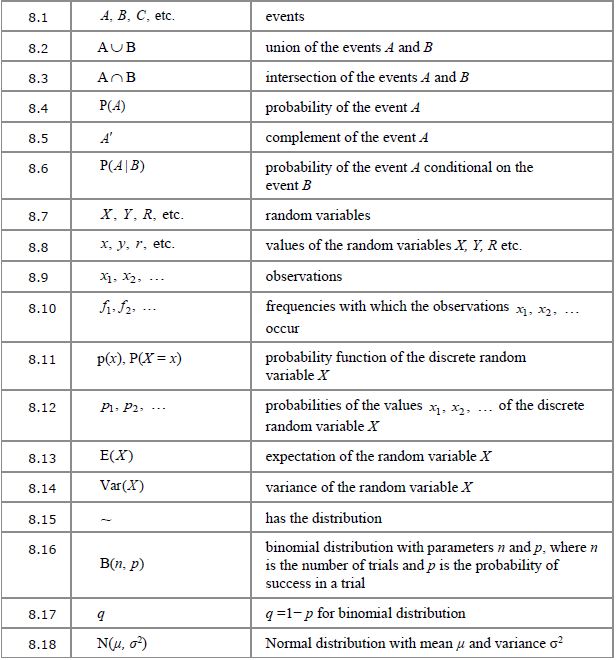
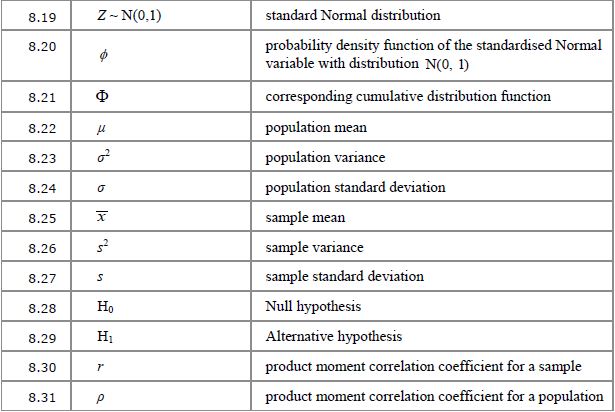
8.1 to 8.6 Set notation for probability
This is already familiar to you from the set notation section; here it’s just being used in the context of probability questions, often with Venn diagrams. The complement of event  , shown as
, shown as  , just means the opposite of , so
, just means the opposite of , so  is the probability of event not happening.
is the probability of event not happening.
8.7 to 8.12 Random variables
This concept is probably best explained using an example. Let’s say you have a bag with five raffle tickets numbered 6 to 10. If you draw a random ticket out of the bag then the probability of drawing, say, ticket number 7, is of course 0.2.
With the notation  , the P represents the probability of something happening, and the bit in the brackets specifies what outcome we’re looking for. Uppercase
, the P represents the probability of something happening, and the bit in the brackets specifies what outcome we’re looking for. Uppercase  is a general description of what the variable is, in this case “the number of the ticket drawn”, and lowercase
is a general description of what the variable is, in this case “the number of the ticket drawn”, and lowercase  specifies which particular outcome we’re looking at the probability for – in this case ticket number 7.
specifies which particular outcome we’re looking at the probability for – in this case ticket number 7.
So in this case,  means “the probability that the ticket number drawn is 7, is 0.2”.
means “the probability that the ticket number drawn is 7, is 0.2”.
Sometimes this is abbreviated to simply  (with a lowercase p), so in this example
(with a lowercase p), so in this example  .
.
It can then be abbreviated even further when listing the probabilites of all the possible outcomes:  is the probability of outcome 1 (in this case that might mean drawing ticket no. 6, so
is the probability of outcome 1 (in this case that might mean drawing ticket no. 6, so  );
);  is the probability of outcome 2 (ticket no. 7,
is the probability of outcome 2 (ticket no. 7,  ), etc.
), etc.
Of course, in this particular example every possible outcome has the same probability, but that won’t always be the case.
8.13, 8.14 and 8.22 to 8.27 Measures of location and spread
A measure of location is an average; at A-level the measure used most often is the mean of a distribution.
 is the expected, or mean, value of a discrete probability distribution.
is the expected, or mean, value of a discrete probability distribution.  is used for the mean calculated from a sample, and
is used for the mean calculated from a sample, and  (Greek lowercase mu) is used for the mean of whole population.
(Greek lowercase mu) is used for the mean of whole population.
A measure of spread tells you how spread out the data in the distribution is. The measure of spread that corresponds to the mean is the standard deviation , which can be described a “a typical distance from the mean”. Of course it depends on the shape of the distribution, but generally, the probability of an observed outcome being within one standard deviation of the mean is about two-thirds.
Finding the standard deviation involves squaring the differences between the observed values and the mean (so that they don’t simply cancel out when added up). Of course this means that, to get a measurement with the right units, we need to take the square root after processing the numbers, and the number that we take the square root of to get the standard deviation is called the variance.
We use  for the standard deviation of a sample and
for the standard deviation of a sample and  for the population standard deviation, so of course
for the population standard deviation, so of course  and
and  are the corresponding variances.
are the corresponding variances.
8.15 to 8.19 Probability distributions
As well as discrete probability distributions where you can write down the probability for every possible outcome (without it being too onerous), you’ll learn about binomial distributions (where you’re counting the number of “successes” out of a fixed number of trials) and normal distributions (commonly encountered with continuous data).
The definition  means “the random variable X is binomially distributed with 30 trials and a probability of success in any one trial of 0.4”. For example X might the number of games of pool won by Sid if he plays 30 games and his chance of winning each game is always 0.4. You can work out the probability of him winning, for example, exactly 8 games (
means “the random variable X is binomially distributed with 30 trials and a probability of success in any one trial of 0.4”. For example X might the number of games of pool won by Sid if he plays 30 games and his chance of winning each game is always 0.4. You can work out the probability of him winning, for example, exactly 8 games ( ) or at least 10 games (
) or at least 10 games ( ).
).
For a normal distribution we might say  or “the random variable Y is normally distributed with a mean of 150 and a variance of 25” (so the standard deviation is 5). Because we’re dealing with a continuous variable, the probability is given by the area under the probability density curve. The area under a point (a single value) is 0 so you can only find probabilities for ranges of values.
or “the random variable Y is normally distributed with a mean of 150 and a variance of 25” (so the standard deviation is 5). Because we’re dealing with a continuous variable, the probability is given by the area under the probability density curve. The area under a point (a single value) is 0 so you can only find probabilities for ranges of values.
8.28 and 8.29 Hypothesis testing
Hypothesis testing is a way of deciding whether something that looks as if it might have changed, actually probably has changed, based on the observation of a single sample.  is the null hypothesis, the assertion that nothing has changed;
is the null hypothesis, the assertion that nothing has changed;  is the alternative hypothesis, which proposes that there has been a change. Essentially you work out the probability of the observed result actually happening if nothing has changed, and if it turns out to be very unlikely then you reject and accept that there probably has been a change.
is the alternative hypothesis, which proposes that there has been a change. Essentially you work out the probability of the observed result actually happening if nothing has changed, and if it turns out to be very unlikely then you reject and accept that there probably has been a change.
8.30 and 8.31 Correlation coefficients
Remember the scatter graphs you did at GCSE, where you talked about strong and weak positive and negative correlations? The product moment correlation coefficient,  for a sample or
for a sample or  (Greek lowercase rho) for the entire population, is a measure of how strong the correlation actually is. It ranges from 1 (perfect positive correlation with all points exactly on the line) down to -1 (perfect negative correlation).
(Greek lowercase rho) for the entire population, is a measure of how strong the correlation actually is. It ranges from 1 (perfect positive correlation with all points exactly on the line) down to -1 (perfect negative correlation).
Mechanics
There probably isn’t very much here that’s new to you.
Note, in 9.4 and 9.5, that we use negative powers in units more at A-level than you did at GCSE, but either form is acceptable.
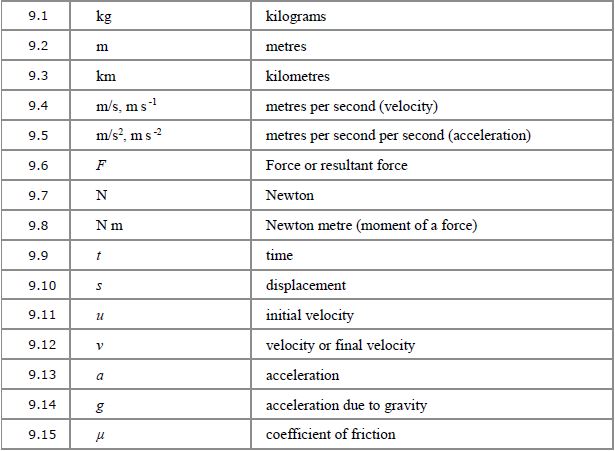
9.8 Moments
You’ll cover these in Year 2 of the A-level. A moment is the turning effect of a force and is given by force × perpendicular distance from the pivot. The units are therefore newtons × metres.
9.9 to 9.14 Constant acceleration (suvat) equations
When acceleration is constant, there’s a set of equations that you can use for kinematics calculations. is used to denote displacement (or distance),  and
and  are initial and final velocities respectively, and of course
are initial and final velocities respectively, and of course  is time.
is time.  is used for acceleration, but if the body is accelerating under gravity then the is replaced by
is used for acceleration, but if the body is accelerating under gravity then the is replaced by  , which is usually – but not always – taken to be 9.8
, which is usually – but not always – taken to be 9.8  .
.
9.15 Friction
This is another 2nd year topic. For any two surfaces in contact, there is a coefficient of friction, , which is between 0 and 1 and depends on how easily the two surfaces slide across each other. The less easily they slide, the higher the value of .
That covers the full set of notation given in the specification.

If you’ve found this article helpful then please share it with anyone else who you think would benefit (use the social sharing buttons if you like). If you have any suggestions for improvement or other topics that you’d like to see covered, then please comment below or drop me a line using my contact form.
On my sister site at at mathscourses.co.uk you can find – among other things – a great-value suite of courses covering the entire GCSE (and Edexcel IGCSE) Foundation content, and the “Flying Start to A-level Maths” course for those who want to get top grades at GCSE and hit the ground running at A-level – please take a look!
If you’d like to be kept up to date with my new content then please sign up to my mailing list using the “Subscribe here” form at the bottom of this page, which will also give you access to my collection of free downloads.
3 Comments